
《人工智能AI之计算机视觉:从像素到智能》 · 模块二:核心感知(上)——2D世界的精细化理解 · 第 9 篇
朋友们好。
在前两篇聊目标检测的文章里,我们就像给AI配上了一把能“框选万物”的神奇尺子。不管是严谨的R-CNN家族,还是闪电般的YOLO流派,核心任务都是:找到物体,并画个框。
但不知道你发现没有,这个“框”其实挺糙的。
它框住了整只猫,却分不清猫和身下的沙发;它框住了行人,却忽略了行人举起的手臂和手里的包。这个框,就像我们小时候描红,只勾勒了一个大概外形,里面的细节一片模糊。现实世界并不是由一个一个方盒子组成的,万物都有复杂、精细、不规则的轮廓。
今天,咱们得聊聊比“看框”更精细的技术——图像分割(Image Segmentation)。它要让AI的理解力从粗糙的“框级”进化到精细的“像素级”。它不再满足于回答“是什么”和“在哪里”,而是要追问每一个像素:“你属于谁?”
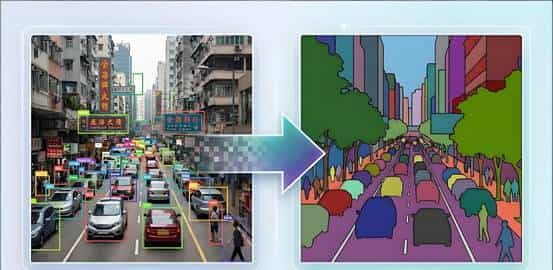
从“框选”到“描摹”的认知进化
一、 拆掉最大的认知误区:“分割”不只是“抠图”
很多人一听“图像分割”,第一反应就是手机里的“一键抠图”或者修图时的“换背景”。
这确实是分割的一种应用,但如果你在电信、银行或保险行业做视觉项目,把“分割”等同于“抠图”,那坑可就大了。分割的本质不是“切开”,而是“归类”。
根据切开的“精细度”和“目的”,分割主要分三类,咱们用生活里的例子拆解一下:
语义分割(Semantic Segmentation):回答“这个像素是什么类别?”
比喻:就像给地图涂色。所有的路涂灰色,所有的车涂蓝色,所有的人涂红色。它只认“类别”,不认“个体”。哪怕路上挤着十个人,在语义分割眼里,他们就是一坨红色的“人”。
实例分割(Instance Segmentation):回答“这个像素属于哪个特定个体?”
比喻:不仅认出是人,还得标出“这是张三,那是李四”。它在区分种类的同时,要把同类中的不同个体清清楚楚地剥离出来。
全景分割(Panoptic Segmentation):语义分割 + 实例分割。
比喻:这是视觉理解的“完全体”。它既要把背景(天空、草地)这种连成片的“东西”分出来,又要把每一个独立的“物体”(车、人、狗)数清楚。
思考小札
从目标检测的“框”到图像分割的“掩膜(Mask,标识像素归属的矩阵)”,本质上是从“定位”思维到“归属”思维的转变。这不仅是技术升级,更是认知维度的跨越:让机器从“看到那里有个东西”,进化到“理解那片区域每一寸土地的身份”。
二、 技术进化史:三把像素级的“手术刀”
要在百万级的像素里做归类,靠传统算法肯定不行。图像分割的发展,其实就是几位“神兵利器”的接力。
2.1 FCN(全卷积网络):把分类模型“拉平”了
2015年之前,分割模型很笨重。FCN(Fully Convolutional Network)的出现打破了僵局。它的思路非常大胆:既然全连接层会丢掉位置信息,那我就把全连接层全扔了,换成卷积层。
创新点:它让网络可以输入任意大小的图片,直接输出一张同样大小的“分类图”。痛点:由于中间经过了多次下采样(下采样,降低分辨率提取特征的操作),输出的结果非常模糊,像马赛克。
2.2 U-Net:医疗影像的“心头好”
为了解决模糊问题,同年诞生的 U-Net 提供了一个极具美学的方案:先压缩理解,再放大还原。
它的结构像一个对称的“U”形:
左边(编码器):负责层层压缩,提取抽象特征。右边(解码器):负责层层放大,恢复细节。神来之笔——跳跃连接(Skip Connection):在放大的时候,直接从左边的对应层把还没弄丢的“细节线稿”传过来。
这就是为什么 U-Net 在医学影像(如勾勒肿瘤边界)和工业质检(如检测芯片细微划痕)里是标配。因为它“不丢边缘”。
2.3 Mask R-CNN:检测与分割的优雅统一
2017年,何恺明大神团队推出了 Mask R-CNN。它的思路很“工程化”:既然 Faster R-CNN 已经能精准找框了,我为什么不在框的基础上再加一个“分割分支”呢?
它就像是在精准定位后,又给AI配了一支细毛笔,在框里细细描摹。它是目前实例分割领域的“王者”,也是很多商业视觉系统集成的首选。
三、 图表辅助理解:三大模型对比
这里梳理一下这三个关键模型的逻辑差:
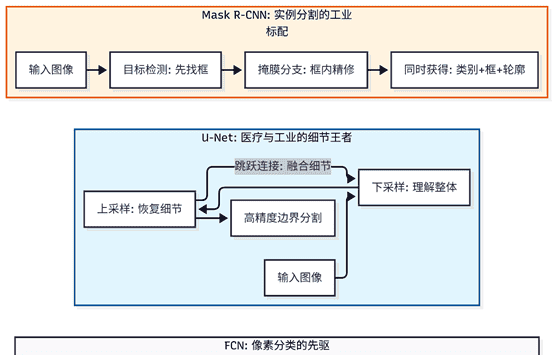
三大模型对比
四、 产业场景:当像素有了“业务价值”
作为一名在电信、金融行业摸爬滚打30多年的IT老兵,我深知:模型不值钱,解决问题的认知才值钱。 在中国,图像分割正在这些地方悄悄改变游戏规则:
4.1 保险定损:从“拍张照”到“精准算”
以前车险理赔,查勘员拍几张照,凭经验判断损失。现在,领先的保险公司(如平安、人保)的后台系统,在你上传照片后,会自动完成三步:
检测:找到车门、保险杠。分割:精细地画出刮擦、凹陷的面积(像素级分割)。精算:通过分割出的面积,自动对比后台配件库和工时费,秒出赔付方案。 这就是把“图像”变成了“数字资产”。
4.2 智慧电信:机房巡检的“火眼金睛”
在电信机房巡检中,光纤跳线像乱麻一样。传统的“看框”根本分不清哪根线压到了哪根线。利用分割技术,AI可以勾勒出每一根跳线的走向,自动判断弯曲半径是否合规、标签是否被遮挡。 这不再是“看到一堆线”,而是“理清了这堆线”。
思考小札
在做金融票据自动化项目时发现,80%的失败不是因为模型不准,而是“业务共识”不清。分割的边界画在哪里?是包含阴影还是不包含?这其实不是技术问题,而是“标注哲学”问题。在银行票据识别中,边界画错一个像素,可能就是万元级的误差。
五、 未来瞭望:分割技术的“无形”进化
技术从未止步。现在的分割正变得越来越聪明:
自注意力机制(Attention)的加入:像 Swin Transformer 这样的模型,让分割有了“全局观”,不再被局部的阴影或遮挡迷惑。边缘部署:以前跑分割需要昂贵的GPU,现在通过模型量化(将模型参数变小的技术),连你家门口的安防摄像头都能实时分割出“危险区域”。
六、 结语:理解世界的边界
如果说:
分类是让机器“睁开眼”;检测是让机器“看见东西”;那么图像分割,就是在教机器——理解世界的边界。
当每一个像素都有了归属,图片就从一堆无意义的色彩矩阵,变成了机器可以理解、可以操作、可以交互的“数字孪生”世界。
那么,下一步的问题会更有意思: 如果不仅要“看清像素”,还要“理解时间里的变化”呢?如果物体在动,甚至我们要从2D的照片里重建出3D的世界呢?
这正是咱们下一个模块要闯入的领域。
💡 互动时刻
本篇小结:咱们拆解了分割的“语义、实例、全景”三种模式,认识了 FCN、U-Net、Mask R-CNN 三大神器,并看了保险和电信领域的真实应用。思考/讨论:你觉得在“自动驾驶”和“手机美颜换背景”这两个场景中,分别应该优先使用“实例分割”还是“语义分割”?为什么?欢迎在评论区聊聊你的见解。术语小词典:
掩膜(Mask):分割的结果图,通常黑白或彩色,标明每个像素的归属。IoU(交并比):衡量分割准不准的核心指标,就是模型划的范围和真实范围的重合度。跳跃连接(Skip Connection):U-Net的精髓,把还没被压缩丢掉的细节直接传给后面,防止边缘变模糊。
我是你的老朋友,深耕IT/CT/AI融合,以多元洞见驱动认知进化。咱们下期见!
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...




