本文是《大模型从0到精通》系列第二卷“构造篇”的第一章。第一卷“奠基篇”五章内容我们建立了完整框架:模型→损失→优化→网络结构→责任追溯。上一章我们知道,没有激活函数的深度网络只是‘纸老虎’。那么,这个让AI拥有‘非线性判断力’的激活函数,到底是怎么工作的?它有哪些‘性格’?。
一、从”直线思维”到”曲线思维”
还记得我们之前说的奶茶店预测模型吗?
销售额 = a × 气温 + b
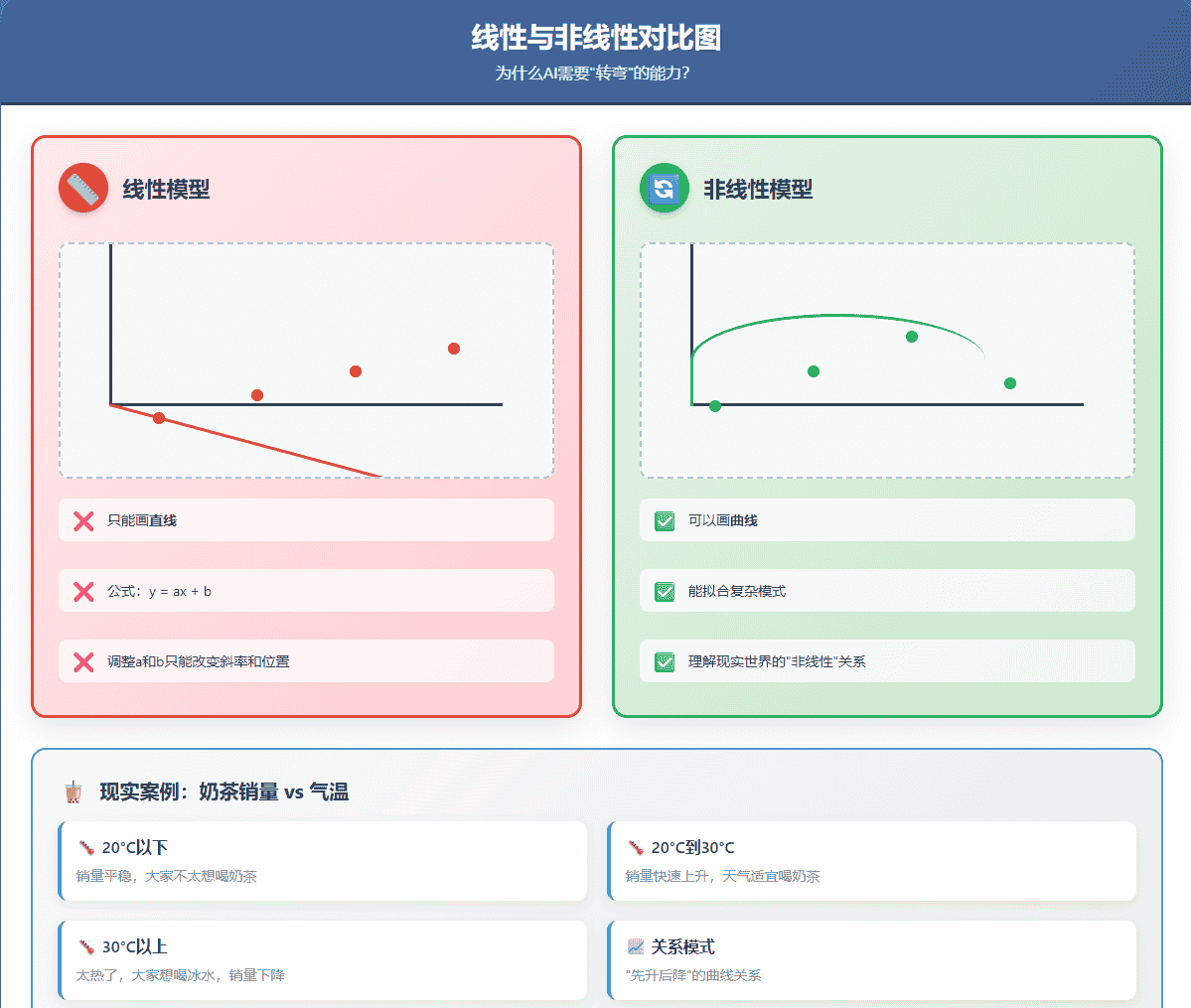
线性模型有个致命缺陷:它只能画直线。
但现实世界哪有那么多直线关系?气温和奶茶销量的关系可能是这样的:
气温20°C以下:销量平稳20°C到30°C:销量快速上升30°C以上:太热了,大家反而想喝冰水,销量下降
这种”先升后降”的曲线,你让
y=ax+b
这就是线性模型的局限:无论你怎么调整a和b这两个旋钮,你只能得到不同斜率和位置的直线,永远得不到一条曲线。
二、激活函数:给AI装上”转弯”的能力
激活函数(Activation Function)就是解决这个问题的关键。
你可以把它想象成一个信号处理器,或者更形象地说,是一个判断官。
每个神经元(就是我们之前说的”小公式”)在计算完自己的线性结果后,不会直接把这个结果传给下一层,而是先交给激活函数这个”判断官”处理一下。
这个”判断官”有个神奇的能力:它能改变信号的形状。
举个例子
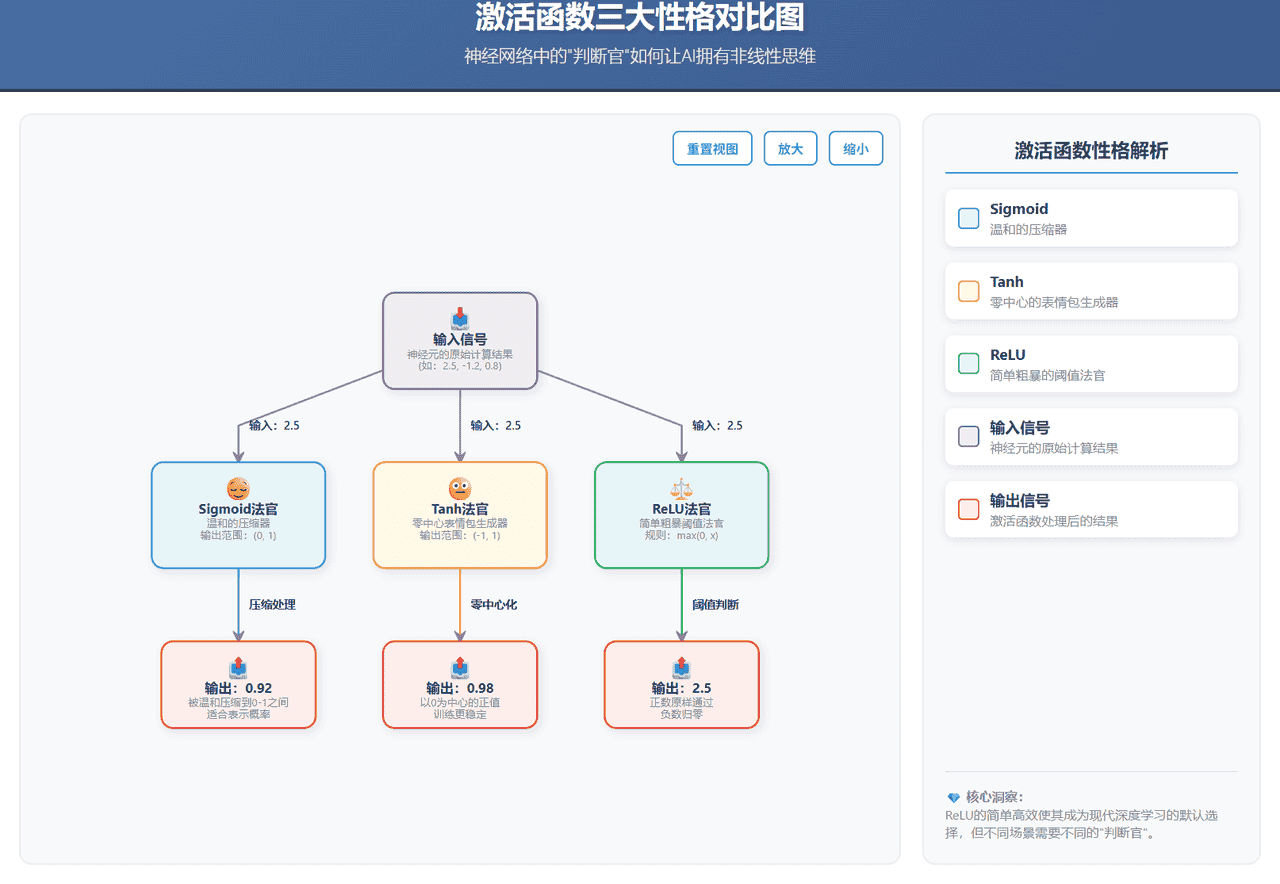
假设一个神经元计算结果是
2.5
不同的激活函数会有不同的处理方式:
Sigmoid法官:温和地说:“嗯,2.5这个数有点大,我给你压缩到0.9左右吧”ReLU法官:干脆利落:“大于0?好,原样通过!”Tanh法官:考虑正负:“2.5是正数,我给你映射到0.98吧”
关键来了:正是这个”处理一下”的动作,让整个神经网络具备了非线性能力。
三、三大”性格”鲜明的激活函数
1. Sigmoid:温和的”压缩器”
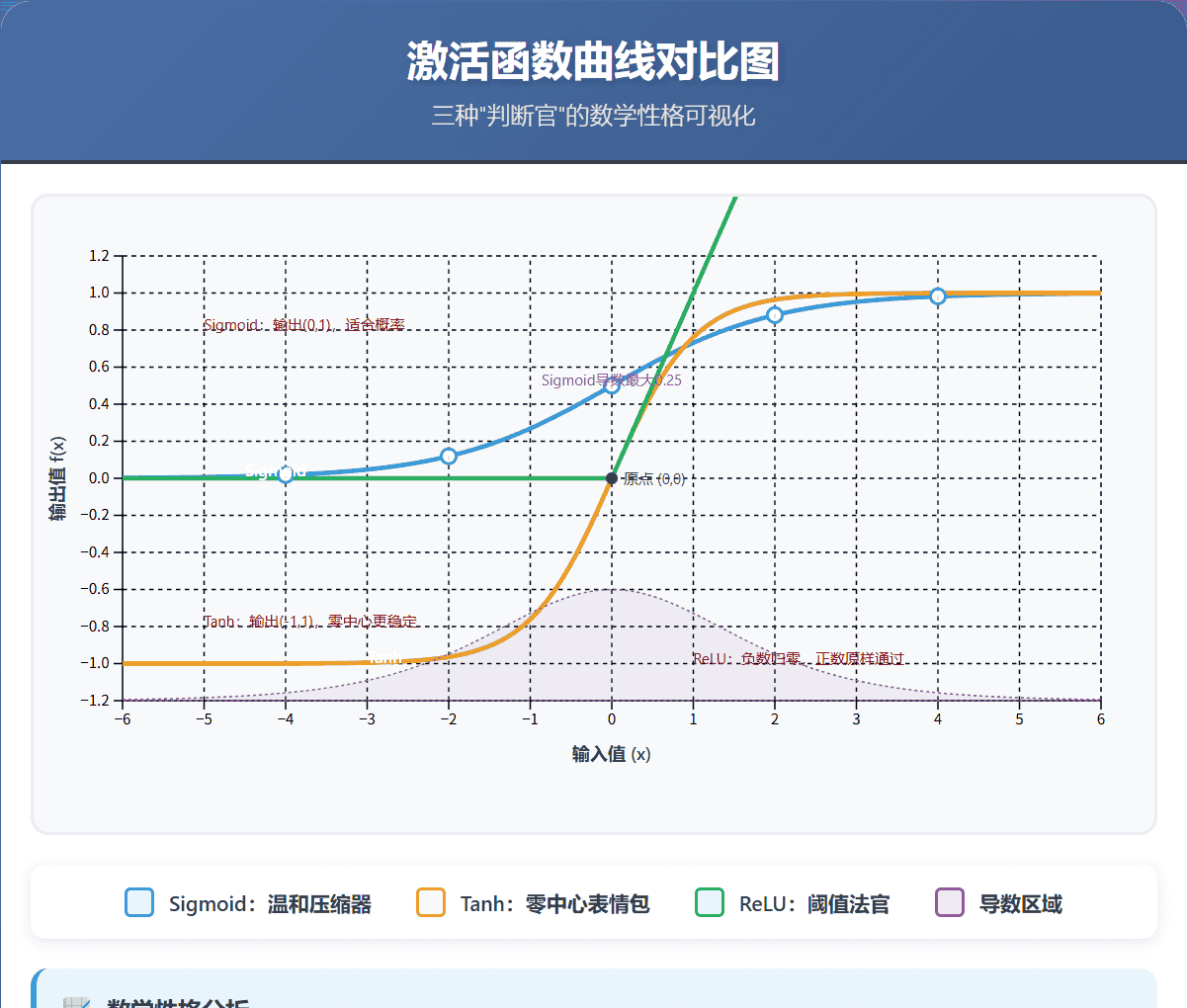
性格特点:情绪稳定,擅长把任何输入都温和地压缩到0到1之间
工作方式:
输入很大正数 → 输出接近1输入很大负数 → 输出接近0输入0 → 输出0.5
比喻:就像一个经验丰富的调解员。无论你带着多么激烈的情绪(很大的正数或负数)来找他,他都能把你安抚到一个温和的状态(0到1之间)。
优点:
输出范围固定(0,1),适合表示概率平滑可导,数学性质好
缺点:
计算量大(要算指数)容易导致”梯度消失”(这个我们下一章详细讲)输出不是以0为中心
适用场景:二分类问题的输出层(需要输出概率时)
2. Tanh:零中心的”表情包生成器”
性格特点:能表达正负情绪,输出以0为中心
工作方式:
输入很大正数 → 输出接近1输入很大负数 → 输出接近-1输入0 → 输出0
比喻:一个能生成正负表情包的工具。给你一个输入,它能判断这是”开心😊”(接近1)还是”难过😢”(接近-1),还是”平静😐”(接近0)。
优点:
输出以0为中心,训练更稳定相比Sigmoid,梯度更强一些
缺点:
同样有梯度消失问题计算量也不小
适用场景:隐藏层,特别是RNN中常用
3. ReLU:简单粗暴的”阈值法官”
性格特点:极度理性,效率至上
工作方式(简单到令人发指):
如果输入 > 0:原样输出如果输入 ≤ 0:输出0
公式就一句话:
f(x) = max(0, x)
比喻:一个没有任何废话的效率狂。“正能量?通过!负能量?归零!”
优点:
计算极其简单(就是比较大小)缓解了梯度消失问题(正数区域梯度为1)训练收敛快
缺点:
“神经元死亡”问题:如果一个神经元总是输出负数,那么经过ReLU后永远输出0,这个神经元就”死”了输出不是以0为中心
适用场景:现代深度学习默认选择,绝大多数隐藏层都用它
四、为什么ReLU能成为”王者”?
你可能觉得奇怪:ReLU这么简单粗暴,为什么反而成了最流行的激活函数?
我刚开始学深度学习时也有这个疑问。后来在实际项目中用了才发现,简单就是最大的优势。
实际体验对比
我在一个图像分类项目里做过对比实验:
用Sigmoid:训练了3个小时,准确率才到85%用ReLU:训练了1个小时,准确率就到了92%
为什么差距这么大?
计算效率:ReLU就是一个
max(0,x)
梯度保持:在正数区域,ReLU的梯度永远是1。这意味着误差信号能很好地反向传播,不会像Sigmoid那样越传越小。
稀疏性:ReLU会让一半的神经元输出0(输入为负时),这实际上让网络变得更”稀疏”。听起来是缺点,但实践中发现,稀疏的网络反而泛化能力更好,不容易过拟合。
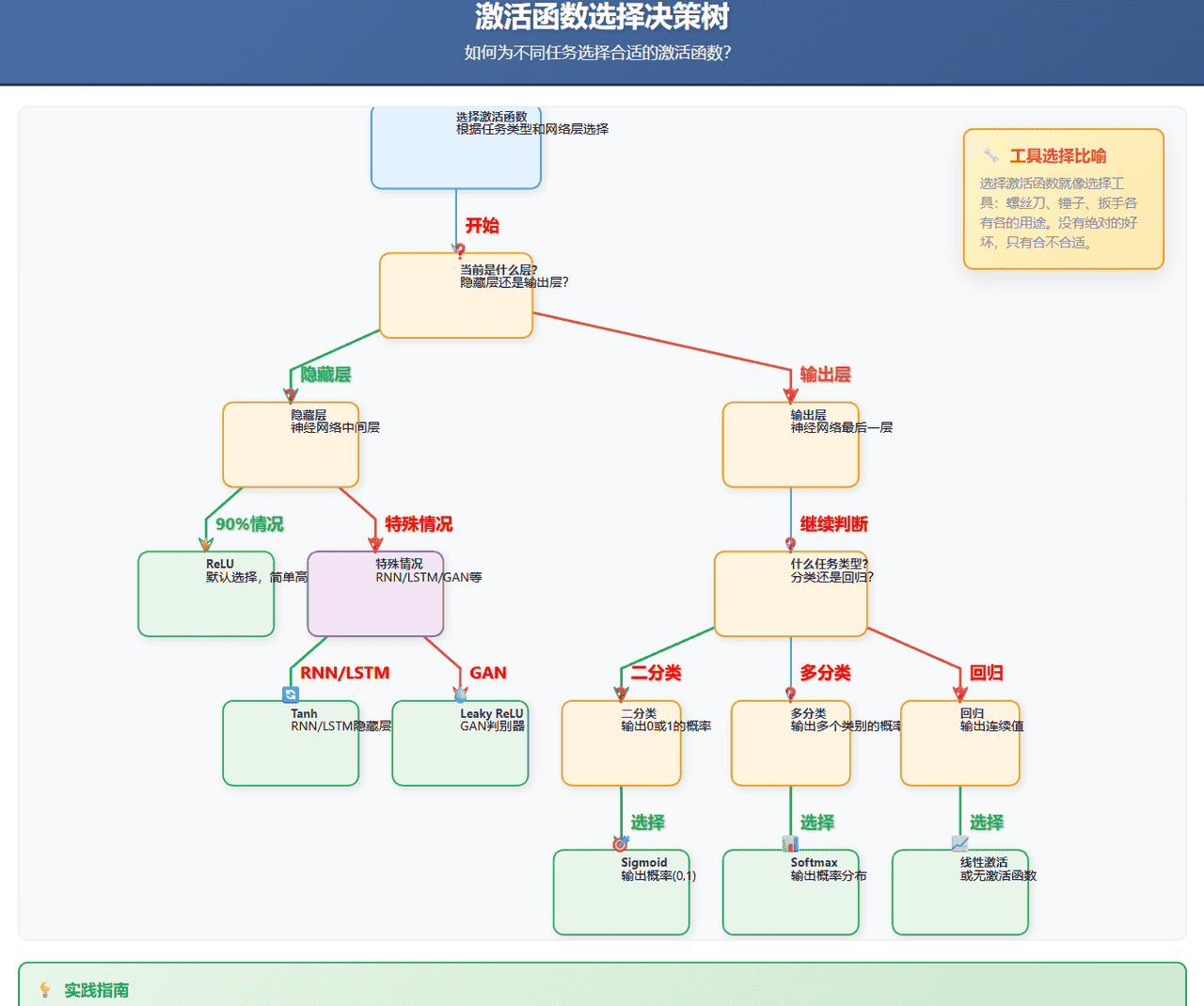
五、激活函数的选择策略
根据我的经验,可以这样选择:
隐藏层:无脑用ReLU
90%的情况,ReLU就是最佳选择如果遇到”神经元死亡”问题,可以试试Leaky ReLU(给负数一个小斜率,比如0.01)
输出层:看任务类型
二分类:Sigmoid(输出概率)多分类:Softmax(输出概率分布)回归问题:线性激活(或者不用激活函数)
特殊情况
RNN/LSTM:Tanh或SigmoidGAN的判别器:Leaky ReLU需要非常平滑的输出:Sigmoid或Tanh
六、一个生动的类比
理解激活函数,我有个很好的类比:
想象你在教AI认动物。
没有激活函数:就像你只告诉AI”看到耳朵+看到四条腿=狗”。这种判断是线性的,太死板。看到兔子(长耳朵+四条腿)也会被认成狗。
有激活函数:就像你告诉AI:
先判断”耳朵长度”(一个神经元)再判断”腿的数量”(另一个神经元)然后判断”体型大小”(又一个神经元)最后,用一个非线性的方式综合这些信息:“如果耳朵很长且腿很短且体型小,那就是兔子;否则再判断…”
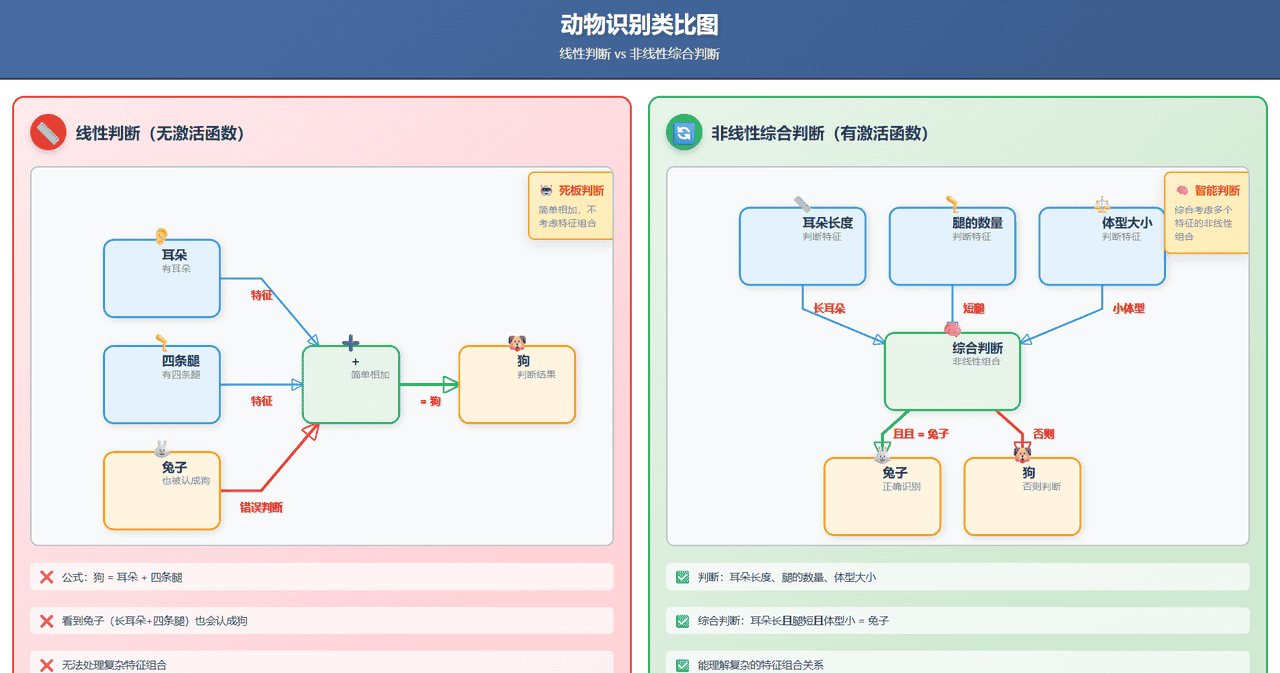
这个”非线性综合”的过程,就是激活函数在起作用。
七、关键要点总结
激活函数是神经网络的”灵魂”:没有它,再深的网络也只是线性模型的堆叠,无法拟合复杂模式。
ReLU是实践中的王者:不是因为它理论上最完美,而是因为它简单、高效、好用。深度学习的很多进步,都来自这种”简单粗暴但有效”的设计。
选择激活函数要看场景:没有绝对的好坏,只有合不合适。就像工具,螺丝刀和锤子各有各的用途。
激活函数让AI有了”判断力”:它让神经网络能从”直线思维”升级到”曲线思维”,从而能理解更复杂的世界。
八、下一步预告
激活函数解决了”非线性”问题,但带来了新的挑战:梯度消失和梯度爆炸。
下一章,我们将深入探讨这个深度学习的”阿喀琉斯之踵”——为什么信号在深网络中会消失或爆炸,以及人们是如何解决这个问题的。
思考题:你能想到现实生活中的哪些”非线性”判断?比如,工资和幸福感的关系是线性的吗?为什么?
本文是《大模型从0到精通》系列的第六章。本系列共5卷16章,将从最基础的数学模型一直讲到最前沿的Agent智能体与RLHF对齐技术。关注我,用最白的话理解最深的AI原理。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...