
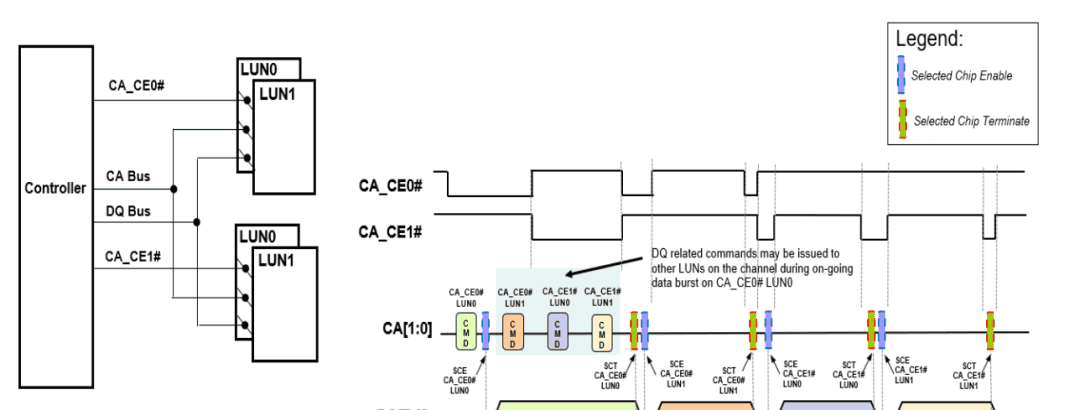
当AI大模型训练动辄吞噬TB级数据、边缘设备实时推理对延迟提出微秒级要求,存储系统正从”数据容器”转变为AI算力的关键支撑。NAND闪存作为现代存储系统的核心组件,其技术迭代始终围绕”速度、容量、可靠性”三大维度展开。最新的ONFI 5.1标准带来了关键革新——分离命令地址(SCA)协议,这一协议通过将命令地址通道与数据通道分离,彻底改变了传统NAND的通信模式。从技术原理来看,SCA协议打破了命令与数据的传输耦合,使得多LUN(逻辑单元)并行操作成为可能,这正是应对AI并行数据访问需求的关键技术基础。
扩展阅读:
浅析下一代NAND接口新特性SCA
3D NAND存储之16KB LDPC困局,谁能成为破局者?
3D NAND与DRAM数据保持失效机制剖析
通过对比数据可以直观看到SCA协议的性能优势:在DDR4800速率下:
4K随机读取场景中,当独立4平面LUN数量达到15个时,SCA协议的读取性能达到799.575 kiops,而传统协议仅为471.893 kiops,性能提升超过70%;
在16K顺序读取场景中,SCA协议更是实现了973.947 kiops的峰值性能,较传统协议提升近一倍。

这种性能飞跃背后,是AI时代存储需求的根本性转变——从单一设备的高速读写,转向大规模并行访问、海量数据吞吐和分层存储架构的协同优化。但矛盾也随之凸显:一方面,AI工作负载要求存储系统具备更高的灵活性和扩展性,支持从云数据中心到边缘设备的全场景部署;

另一方面,NAND技术本身面临着性能瓶颈、信号质量衰减、能耗控制难度加大等多重挑战。

传统集中式控制器架构在应对这些挑战时逐渐力不从心,主要体现在三个方面:
一是并行访问效率不足,难以充分发挥多芯片、多LUN的并发潜力;
二是信号完整性随速率提升急剧下降,制约了接口速度的进一步突破;
三是功能固化,无法灵活适配AI推理优化、GPU IO等多样化需求。

Silicon Motion提出的一种分布式控制器架构,以”DPU+FPU”的模块化设计打破了传统架构的局限,其核心创新在于将存储控制的”管理职能”与”执行职能”分离,实现了灵活性与高性能的统一。

分布式架构的核心是两个功能互补的核心组件:
DPU:作为系统的”大脑”,承担NVMe协议处理、FTL(闪存转换层)管理、垃圾回收(GC)、近数据处理等核心管理任务,同时集成SerDes/PCIe交换机、压缩去重、AI推理加速器等扩展模块。DPU的设计重点是智能化与多功能性,能够适配不同场景的存储管理需求,从主流消费级到高端企业级均可灵活配置。

FPU:作为面向NAND的”专用执行器”,专注于闪存访问的底层操作,包括错误重试、介质健康监测、物理地址映射等”脏活累活”,提供透明无差错的NAND访问能力。FPU的设计亮点在于高度定制化,可根据应用场景分为企业级FPU、专用顺序读取FPU、支持512B GPU IO的FPU等多种类型,实现精准适配。

这种分离式设计带来了显著的架构优势:
在扩展性上,4通道主流配置可采用”1个DPU+4个FPU”组合,8通道高性能配置则可扩展为”1个DPU+2组4通道FPU”,按需扩容;
在数据传输效率上,ONFI总线上的编码数据(含LDPC校验位)在SerDes接口处转为纯数据传输,减少了无效数据开销,同时降低功耗;
在热分布上,模块化布局避免了集中式控制器的散热瓶颈;
在容错性上,DPU(12nm工艺)与FPU(6nm工艺)可采用zig-zag更新模式,提升系统稳定性。
扩展阅读:
3D NAND存储之16KB LDPC困局,谁能成为破局者?
论文解读:NAND闪存中读电压和LDPC纠错码的高效设计
SSD LDPC软错误探测方案解读
关于SSD LDPC纠错能力的基础探究
浅析LDPC软解码对SSD延迟的影响
分布式架构的性能发挥,离不开信号处理技术的革新。传统NAND控制器在应对高速传输时,常采用模拟开关、Re-driver或Re-timer进行信号调理,但这些方案各有局限:模拟开关无协议感知能力,重驱动器会放大噪声,重定时器则存在较大延迟。

FPU作为分布式架构的关键执行单元,集成了信号调理与协议处理功能,形成了独特的技术优势:
全协议感知能力:不仅支持传统协议,更深度适配ONFI 5.1的SCA协议,无需额外芯片即可实现高速通信;
最优抖动控制:通过混合信号设计(模拟PHY+数字逻辑),同时补偿码间干扰(ISI)和随机抖动,重置抖动预算,彻底解决高速传输下的信号质量问题;
零额外延迟:虽然内部存在流水线延迟,但相比传统方案省去了外部芯片的传输开销,实现了传统协议与SCA协议的无感知切换。
Silicon Motion已计划在2025年底通过TSMC流片验证FPU测试芯片,该芯片配备两个ONFI接口,可通过充分利用NAND裸片资源使数据带宽翻倍,这一进展将为分布式架构的商业化落地奠定关键基础。

AI时代的存储控制器,正从”被动响应”转向”主动智能”。分布式架构通过两大技术路径实现智能化升级:
计算存储一体化(CIS):将部分计算任务迁移至存储层,在数据本地完成预处理、筛选和简单推理,减少数据在存储与CPU/GPU间的传输延迟,尤其适配AI推理场景的低延迟需求;
QoS与延迟管理:通过智能调度算法,为不同AI任务分配差异化的存储资源,保障关键任务的延迟稳定性,同时优化整体吞吐量。
这种智能化升级,使得存储系统不再是AI算力的”拖油瓶”,而是成为协同计算的重要组成部分,为AI模型的高效运行提供底层支撑。分布式控制器架构的出现,将从根本上缓解NAND技术的性能瓶颈,推动存储系统向”高并行、高智能、高灵活”方向发展。
对于NAND厂商而言,这一架构降低了对单一芯片性能的极致追求,转而通过系统级优化实现整体性能提升,为3D NAND的持续堆叠和密度提升创造了更大空间;对于AI企业而言,分布式存储方案可根据不同场景(云数据中心、AI工厂、边缘设备)进行定制化配置,实现存储资源与AI算力的精准匹配。
AI时代的NAND存储将呈现四大发展趋势:
芯粒(Chiplet)技术深化:通过芯粒集成实现DPU与FPU的异构封装,进一步提升系统集成度和性能密度,同时降低研发成本;
全场景AI适配:从云端大模型训练到边缘设备实时推理,存储系统将形成覆盖全场景的产品矩阵,支持从TB级到GB级的灵活容量配置和从微秒级到毫秒级的延迟优化;
自主智能存储:控制器将具备更强的自优化、自诊断能力,能够根据AI任务的运行状态动态调整存储策略,实现性能与能耗的平衡;
生态协同深化:NAND厂商与AI平台提供商的合作将更加紧密,存储系统将深度集成AI框架和硬件,形成”算力-存储-算法”的协同优化生态。
尽管分布式架构优势显著,但仍面临两大挑战:一是设计复杂度提升,混合信号处理、多模块协同等技术需要更高的研发投入;二是生态适配成本,需要与NAND芯片、AI硬件、软件框架进行深度兼容测试。对此,可以通过标准化接口(如ONFI 5.1)降低适配难度,同时开放部分定制化接口,满足不同客户的个性化需求。
在AI技术飞速发展的今天,存储系统的革新往往被算力的光芒所掩盖,但正是这种”幕后英雄”的突破,才支撑起AI大模型的持续进化。分布式控制器架构,以模块化设计破解了NAND存储的性能困局,以智能化升级重构了存储与AI的协同关系,为AI时代的存储革命提供了清晰的技术路径。
未来,随着芯粒技术、计算存储融合、生态协同的不断深化,存储系统将不再是简单的数据容器,而是成为AI能力的延伸,为”AI无处不在”的愿景提供坚实支撑。对于行业而言,这一架构的落地不仅将推动存储技术的迭代升级,更将加速AI在各行业的规模化应用,开启智能存储与AI协同发展的全新篇章。
参考文献:
FMS2025-Silicon Motion-《A Distributed Controller for Flexible Applications in the AI Era》
如果您看完有所受益,欢迎点击文章底部左下角“关注”并点击“分享”、“在看”,非常感谢!
精彩推荐:
基于CXL内存的热数据检测技术解读
学术前沿|专为CXL SSD设计的文件系统
2025伊始,PCIe 7.0的脚步更近了
存储随笔2024年度技术分享总结
浅析下一代NAND接口新特性SCA
2025年CXL强势启航:开启内存扩展新时代
PCIe SSD在温变环境的稳健性技术剖析
DWPD指标:为何不再适用于大容量SSD?
突破内存墙:DRAM的过去、现在与未来
E1.S接口如何解决SSD过热问题?
ZNS SSD是不是持久缓存的理想选择?
存储正式迈入超大容量SSD时代!
FMS 2024: 带来哪些存储技术亮点?
IEEE报告解读:存储技术发展趋势分析
PCIe P2P DMA全景解读
深度解读NVMe计算存储协议
浅析不同NAND架构的差异与影响
浅析PCI配置空间
浅析PCIe系统性能
存储随笔《NVMe专题》大合集及PDF版正式发布!
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











