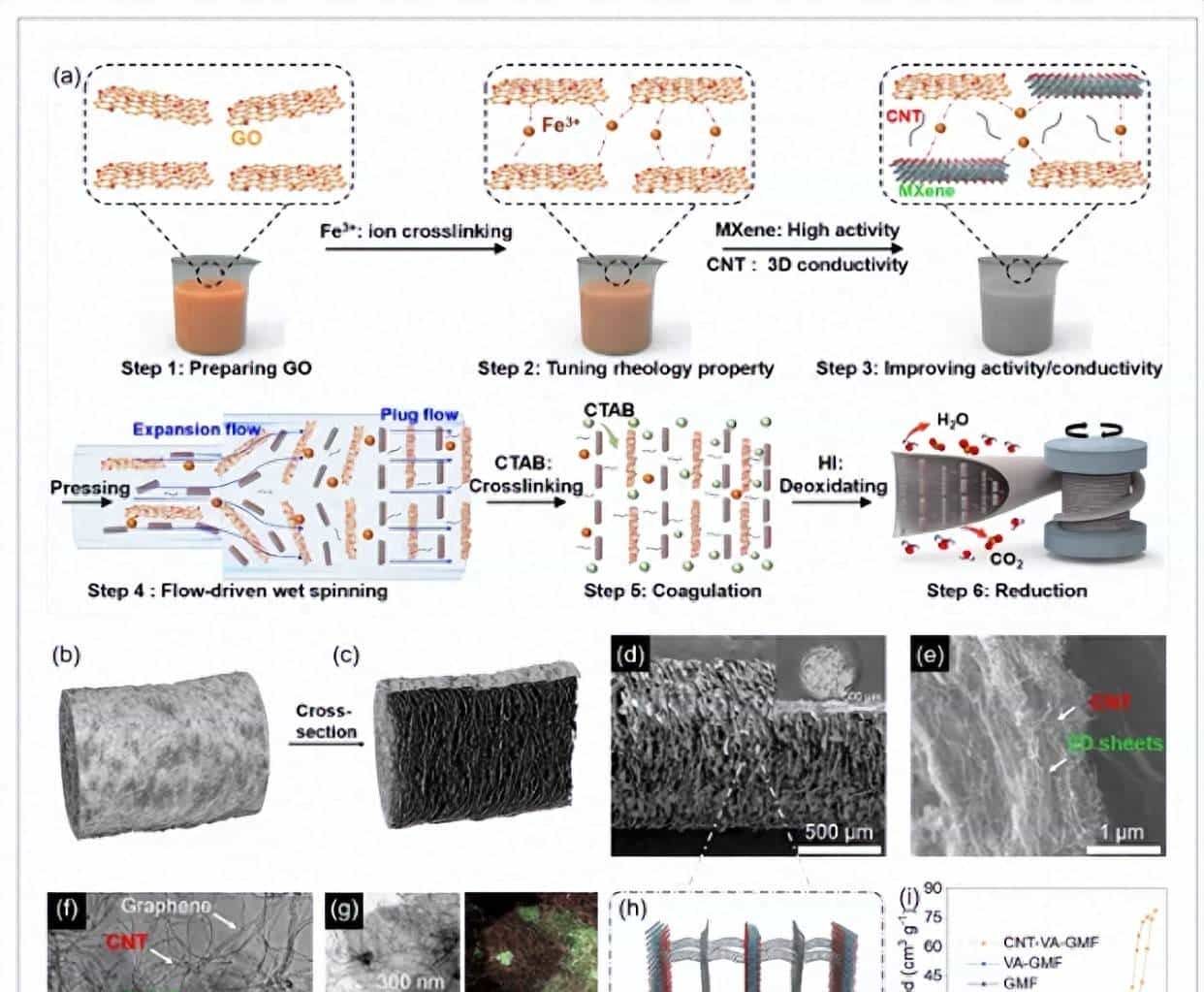
前言
受够了Excel的折磨。今天,进阶版来了!这100个全新不重复的单行代码,将带你进入Pandas的更高境界!

一、高级读取与导出(101-120行)
# 101. 读取含合并单元格的Excel,自动展开
df = pd.read_excel('merged_cells.xlsx', header=None).ffill(axis=0)
# 102. 跳过表头读取(从第3行开始)
df = pd.read_excel('data.xlsx', skiprows=2)
# 103. 读取指定行范围(第5到50行)
df = pd.read_excel('data.xlsx', skiprows=range(1,4), nrows=46)
# 104. 处理千分位分隔符(如1,000)
df = pd.read_excel('data.xlsx', thousands=',')
# 105. 自定义日期解析格式
df = pd.read_excel('data.xlsx', parse_dates=['date'], date_parser=lambda x: pd.to_datetime(x, format='%Y年%m月%d日'))
# 106. 读取时重命名列
df = pd.read_excel('data.xlsx', names=['新列1', '新列2', '新列3'])
# 107. 读取Excel中的公式结果(而非公式本身)
df = pd.read_excel('with_formulas.xlsx', engine='openpyxl')
# 108. 导出到Excel时隐藏网格线
df.to_excel('output.xlsx', index=False).save()
# 配合xlsxwriter可实现更多格式控制
# 109. 保存为加密Excel文件
df.to_excel('encrypted.xlsx', index=False, engine='xlsxwriter', encryption={'password': 'mypass'})
# 110. 追加数据到现有Excel文件(不覆盖)
with pd.ExcelWriter('existing.xlsx', mode='a', engine='openpyxl') as writer:
df.to_excel(writer, sheet_name='NewData', index=False)
# 111. 保存数据时自动添加筛选器
df.to_excel('with_filter.xlsx', index=False, freeze_panes=(1,0))
# 112. 导出时保留列宽设置
df.to_excel('output.xlsx', index=False).style.set_properties(**{'text-align': 'left'})
# 113. 读取多个类似文件并自动对齐列
dfs = [pd.read_excel(f).reindex(columns=master_columns) for f in file_list]
# 114. 读取包含多个标题行的Excel
df = pd.read_excel('multi_header.xlsx', header=[0,1]) # 两级标题
# 115. 导出时添加条件格式(高亮最大值)
(df.style
.apply(lambda x: ['background-color: yellow' if v == x.max() else '' for v in x], subset=['sales'])
.to_excel('highlighted.xlsx'))
# 116. 读取时自动检测编码
df = pd.read_excel('data.xlsx', encoding_errors='ignore')
# 117. 导出时创建数据验证下拉列表(需xlsxwriter)
# 需要配合worksheet.data_validation()使用
# 118. 读取时处理注释单元格(只读数值)
df = pd.read_excel('with_comments.xlsx', engine='openpyxl', data_only=True)
# 119. 导出时设置打印区域
# 通过worksheet.print_area()设置
# 120. 批量重命名导出文件(根据内容)
df.to_excel(f"report_{df['date'].iloc[0].strftime('%Y%m')}.xlsx")二、智能数据清洗(121-140行)
# 121. 智能识别并转换日期格式
df['date'] = pd.to_datetime(df['date'], errors='coerce', infer_datetime_format=True)
# 122. 删除99%以上重复值的列
df = df.loc[:, df.nunique() / len(df) > 0.01]
# 123. 自动检测并处理异常值(IQR方法)
Q1 = df['sales'].quantile(0.25)
Q3 = df['sales'].quantile(0.75)
IQR = Q3 - Q1
df = df[~((df['sales'] < (Q1 - 1.5 * IQR)) | (df['sales'] > (Q3 + 1.5 * IQR)))]
# 124. 用分组均值填充缺失值
df['sales'] = df.groupby('dept')['sales'].transform(lambda x: x.fillna(x.mean()))
# 125. 处理数字中的中文单位(如"1万元")
df['amount'] = df['amount_str'].str.extract('(d+)').astype(float) * 10000
# 126. 拆分合并单元格内容(如"张三/李四")
df[['first_person', 'second_person']] = df['names'].str.split('/', expand=True)
# 127. 统一中文数字为阿拉伯数字
cn_to_arabic = {'一':1, '二':2, '三':3, '四':4, '五':5}
df['number'] = df['chinese_number'].map(cn_to_arabic)
# 128. 提取字符串中的数字
df['extracted_number'] = df['mixed'].str.extract('(d+)').astype(float)
# 129. 清洗电话号码格式
df['phone'] = df['phone'].str.replace(r'D', '', regex=True).str.slice(0, 11)
# 130. 身份证号验证与信息提取
df['birth_year'] = df['id_card'].str.slice(6, 10).astype(int)
# 131. 自动识别并转换百分比字符串
df['rate'] = df['percent_str'].str.rstrip('%').astype(float) / 100
# 132. 处理科学计数法字符串
df['value'] = pd.to_numeric(df['scientific_str'], errors='coerce')
# 133. 统一日期格式(多种格式混合时)
df['date'] = pd.to_datetime(df['date'], format='mixed', dayfirst=True, errors='coerce')
# 134. 删除前后特殊字符
df['text'] = df['text'].str.strip('
fvxa0')
# 135. 智能截断过长文本
df['short_text'] = df['long_text'].str.slice(0, 50) + '...'
# 136. 检测并删除不可见字符
df['clean'] = df['dirty'].str.replace(r'[x00-x1Fx7F-x9F]', '', regex=True)
# 137. 统一英文大小写(首字母大写)
df['name'] = df['name'].str.title()
# 138. 中文数字排序转换
df = df.sort_values('chinese_number', key=lambda x: x.map({'一':1, '二':2, '三':3}))
# 139. 处理全半角字符
df['text'] = df['text'].str.replace(',', ',').str.replace('。', '.')
# 140. 自动识别并拆分地址信息
df[['province', 'city', 'district']] = df['address'].str.split('/', expand=True)三、高级筛选与查询(141-160行)
# 141. 正则表达式高级筛选
df_filtered = df[df['text'].str.contains(r'^[A-Z]{3}-d{4}$', regex=True)]
# 142. 筛选包含列表任一元素的行
keywords = ['紧急', '重大', '加急']
df_filtered = df[df['title'].str.contains('|'.join(keywords))]
# 143. 筛选特定时间段的记录
df_time = df[df['datetime'].between('2023-06-01', '2023-06-30')]
# 144. 筛选数值在某个区间的记录
df_range = df[df['score'].between(60, 100, inclusive='both')]
# 145. 筛选文本长度大于某值的记录
df_long = df[df['description'].str.len() > 100]
# 146. 筛选某列值出现频率最高的前N个类别
top_categories = df['category'].value_counts().head(5).index
df_top = df[df['category'].isin(top_categories)]
# 147. 筛选连续出现N次以上的记录
df['consecutive'] = (df['status'] != df['status'].shift()).cumsum()
df_filtered = df.groupby('consecutive').filter(lambda x: len(x) >= 3)
# 148. 筛选分组后各组的前N名
df_top3 = df.groupby('dept').apply(lambda x: x.nlargest(3, 'sales')).reset_index(drop=True)
# 149. 排除测试数据或特定标记
df_clean = df[~df['remark'].str.contains('测试|示例|demo', case=False, na=False)]
# 150. 筛选最近N天的数据
recent = df[df['date'] > pd.Timestamp.now() - pd.Timedelta(days=7)]
# 151. 多列联合去重(基于关键列组合)
df_unique = df.drop_duplicates(subset=['col1', 'col2', 'col3'])
# 152. 筛选工作日数据
df_workdays = df[df['date'].dt.weekday < 5]
# 153. 筛选季度末数据
df_qend = df[df['date'].dt.month.isin([3, 6, 9, 12]) & (df['date'].dt.day >= 25)]
# 154. 通配符筛选(类似Excel的*和?)
df_wildcard = df[df['product_code'].str.match(r'ABC-d{3}.*')]
# 155. 排除包含特定词的记录
df_exclude = df[~df['notes'].str.contains('已撤销|作废', na=False)]
# 156. 筛选增长率超过阈值的记录
df['growth'] = df.groupby('product')['sales'].pct_change()
df_high_growth = df[df['growth'] > 0.5]
# 157. 筛选组合条件复杂的记录(使用query)
df_complex = df.query('(sales > 1000 and profit_rate > 0.2) or (dept in ["A", "B"] and month == "Q4")')
# 158. 筛选变化幅度大的记录
df['change'] = df['price'].diff().abs()
df_big_change = df[df['change'] > df['price'].mean() * 0.1]
# 159. 筛选满足自定义函数的记录
def is_valid(row):
return row['age'] >= 18 and row['score'] >= 60
df_valid = df[df.apply(is_valid, axis=1)]
# 160. 筛选连续递增/递减的记录
df['increasing'] = df['value'].diff() > 0
df_consecutive_inc = df[df['increasing'].rolling(window=3).sum() == 3]四、高级转换与计算(161-180行)
# 161. 计算移动加权平均
weights = [0.1, 0.2, 0.3, 0.4]
df['weighted_ma'] = df['sales'].rolling(window=4).apply(lambda x: np.dot(x, weights))
# 162. 计算同期对比增长率(YoY)
df['yoy_growth'] = df.groupby('month')['sales'].pct_change(periods=12) * 100
# 163. 计算累计占比(累计贡献率)
df['cum_pct'] = df['sales'].cumsum() / df['sales'].sum()
# 164. 计算Z-score标准化
df['z_score'] = (df['value'] - df['value'].mean()) / df['value'].std()
# 165. Min-Max归一化(缩放到0-1)
df['normalized'] = (df['value'] - df['value'].min()) / (df['value'].max() - df['value'].min())
# 166. 计算分位数(四分位、十分位)
df['quartile'] = pd.qcut(df['score'], q=4, labels=['Q1', 'Q2', 'Q3', 'Q4'])
# 167. 计算排名(思考并列)
df['rank'] = df['score'].rank(method='dense', ascending=False)
# 168. 计算百分位数
df['percentile'] = df['score'].rank(pct=True) * 100
# 169. 计算滚动相关系数
df['rolling_corr'] = df['x'].rolling(window=20).corr(df['y'])
# 170. 计算指数移动平均(EMA)
df['ema'] = df['price'].ewm(span=12).mean()
# 171. 计算复利增长率(CAGR)
n_years = (df['date'].max() - df['date'].min()).days / 365.25
df['cagr'] = ((df['ending'] / df['beginning']) ** (1/n_years) - 1)
# 172. 计算基尼系数(不平等程度)
sorted_vals = df['income'].sort_values()
n = len(sorted_vals)
df['gini'] = 1 - 2/(n-1) * (n - (sorted_vals.cumsum() / sorted_vals.sum()).sum())
# 173. 计算赫芬达尔指数(市场聚焦度)
df['hhi'] = (df['market_share'] ** 2).sum()
# 174. 计算信息熵(不确定性)
probs = df['category'].value_counts(normalize=True)
df['entropy'] = -(probs * np.log2(probs)).sum()
# 175. 计算波动率(标准差)
df['volatility'] = df['return'].rolling(window=20).std() * np.sqrt(252)
# 176. 计算夏普比率
risk_free_rate = 0.02
df['sharpe'] = (df['return'].mean() - risk_free_rate) / df['return'].std()
# 177. 计算最大回撤
df['cumulative'] = (1 + df['return']).cumprod()
df['running_max'] = df['cumulative'].cummax()
df['drawdown'] = df['cumulative'] / df['running_max'] - 1
# 178. 计算分组内的标准化分数
df['group_z'] = df.groupby('category')['score'].transform(lambda x: (x - x.mean()) / x.std())
# 179. 计算滚动偏度和峰度
df['rolling_skew'] = df['returns'].rolling(window=60).skew()
df['rolling_kurt'] = df['returns'].rolling(window=60).kurt()
# 180. 计算滞后项和超前项(时间序列特征)
df['lag1'] = df['sales'].shift(1)
df['lead1'] = df['sales'].shift(-1)五、数据透视与分组(181-200行)
# 181. 创建多层索引的数据透视表
pivot = pd.pivot_table(df, values='sales', index=['year', 'quarter'], columns=['region', 'product'], aggfunc='sum')
# 182. 数据透视表同时计算多个聚合函数
pivot_multi = pd.pivot_table(df, values=['sales', 'profit'], index='dept', aggfunc={'sales':'sum', 'profit':'mean'})
# 183. 数据透视表添加总计行/列
pivot_total = pd.pivot_table(df, values='sales', index='dept', aggfunc='sum', margins=True, margins_name='总计')
# 184. 数据透视表填充空值为0
pivot_filled = pd.pivot_table(df, values='sales', index='dept', columns='month', aggfunc='sum', fill_value=0)
# 185. 数据透视表计算百分比构成
pivot = pd.pivot_table(df, values='sales', index='product', aggfunc='sum')
pivot['pct'] = pivot['sales'] / pivot['sales'].sum()
# 186. 数据透视表添加排序
pivot_sorted = pd.pivot_table(df, values='sales', index='dept', aggfunc='sum').sort_values('sales', ascending=False)
# 187. 交叉表计算占比(按行/列)
cross_pct = pd.crosstab(df['dept'], df['level'], normalize='index') # 行百分比
# 188. 交叉表添加边际总计
cross_total = pd.crosstab(df['dept'], df['level'], margins=True)
# 189. 分组后计算多个统计量
grouped_stats = df.groupby('dept').agg(
total_sales=('sales', 'sum'),
avg_profit=('profit', 'mean'),
count=('id', 'count'),
std_sales=('sales', 'std')
)
# 190. 分组计算累积值
df['cumsum_by_group'] = df.groupby('dept')['sales'].cumsum()
# 191. 分组计算排名
df['rank_in_group'] = df.groupby('dept')['sales'].rank(ascending=False)
# 192. 分组计算与前值的差异
df['diff_in_group'] = df.groupby('dept')['sales'].diff()
# 193. 分组计算移动平均
df['ma_by_group'] = df.groupby('dept')['sales'].rolling(window=3).mean().reset_index(0, drop=True)
# 194. 分组筛选(保留每组前N%)
df_top_pct = df.groupby('dept').apply(lambda x: x.nlargest(int(len(x)*0.2), 'sales'))
# 195. 分组计算组内归一化
df['normalized_in_group'] = df.groupby('dept')['score'].transform(lambda x: (x - x.min()) / (x.max() - x.min()))
# 196. 分组计算组间对比(与整体平均对比)
overall_mean = df['sales'].mean()
df['vs_overall'] = df.groupby('dept')['sales'].transform('mean') / overall_mean
# 197. 分组计算贡献度变化
df['contribution'] = df.groupby('dept')['sales'].transform(lambda x: x / x.sum())
df['contribution_change'] = df.groupby('dept')['contribution'].diff()
# 198. 分组计算同期对比
df['same_period_last_year'] = df.groupby(['dept', df['date'].dt.month])['sales'].shift(12)
# 199. 分组计算复合指标
df['composite_score'] = df.groupby('dept').apply(lambda x: x['sales']*0.6 + x['profit']*0.4).reset_index(level=0, drop=True)
# 200. 终极技巧:完整的数据分析管道
final_report = (pd.concat([pd.read_excel(f).assign(source=f) for f in glob('*.xlsx')])
.query('sales > 0 and profit > 0')
.assign(profit_margin=lambda x: x['profit']/x['sales'],
month=lambda x: x['date'].dt.to_period('M'))
.groupby(['dept', 'month'])
.agg({'sales':'sum', 'profit':'mean', 'profit_margin':'mean'})
.unstack(level=0)
.round(3)
.style.background_gradient(subset=pd.IndexSlice[:, pd.IndexSlice[:, 'sales']], cmap='Blues')
.format({'profit_margin':'{:.1%}', 'profit':'¥{:,.0f}', 'sales':'¥{:,.0f}'})
.to_excel('final_analysis.xlsx', engine='openpyxl'))六、实战应用场景
场景1:自动生成月度经营分析报告
# 原来需要半天的工作,目前一行代码搞定
(report := pd.ExcelWriter('经营分析_202312.xlsx') and
[df.groupby('事业部').agg(指标1=..., 指标2=...).to_excel(report, sheet_name=s)
for s, df in data_dict.items()] and
report.save())场景2:实时监控数据异常
# 自动检测并告警数据异常
alert_df = df[(df['current']/df['baseline']-1).abs()>0.3].to_dict('records')
if alert_df: send_email_alert(alert_df)掌握这些技巧后,你将能够:
- 处理任何复杂格式的Excel文件
- 自动化90%的日常报表工作
- 实现实时数据监控和预警
- 构建专业级的数据分析报告
最后的重大提醒
这200行代码是一个完整的工具箱,但不是要你全部记住!关键是:
- 理解原理 – 知道每类操作能解决什么问题
- 建立索引 – 收藏本文,遇到问题时快速查找
- 组合使用 – 把简单的单行代码组合成复杂的数据管道
你的支持是我继续分享的动力!
如果这100个新技巧帮到了你:
- 点赞 – 让更多需要的人看到
- 关注 – 不错过后续的进阶内容
- 分享 – 协助你的同事和朋友一起提升
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











