AI模型评测—
ClueBenchmarks 网站提供全面的中文大模型基准测评、排行榜及相关数据资源,协助用户评估不同模型在各种自然语言处理任务中的表现。
主要功能和内容列表(按重大程度排序)
-
小样本学习与零样本学习评测
-
大模型基准测评与排行榜
-
用户个人中心与API服务
-
模型能力分析(基础能力榜单、中文特性榜单、开源榜单)
-
数据集和项目资源(DataCLUE榜、KgCLUE、论文、Demo)
-
多样化中文任务评测(SuperCLUE、Agent中文场景、阅读理解等)
| 功能模块 |
详细内容 |
重点说明 |
| 数据与资源 |
CLUE社区、ClueAI、关于CLUE、CLUE介绍、联系我们、常见问题、API与Demo、KgCLUE.Demo、KgCLUE.项目、论文、项目地址、数据集搜索、大模型报告 |
提供完整的学习、研究和使用资源,包括数据集、论文、API接口和演示 |
| 任务与榜单 |
Agent中文场景、Safety安全对抗、OPEN多轮开放式、OPT三大能力客观题、Llama2中文版基准、pCLUE、KgCLUE1.0、分类排行榜1.1/1.0、阅读理解榜1.1/1.0、总排行榜1.1/1.0、DataCLUE榜、语义匹配榜、小样本学习、多、小样本学习、零样本学习、NER排行榜、自然语言推理、小模型榜、NLPCC20小模型 |
提供各类任务和能力榜单,便于模型能力对比和分析 |
| 用户中心 |
登陆、注册、个人得分情况、数据集管理、个人中心、修改密码、退出 |
管理用户信息、访问个人测评结果、数据集及账户设置 |
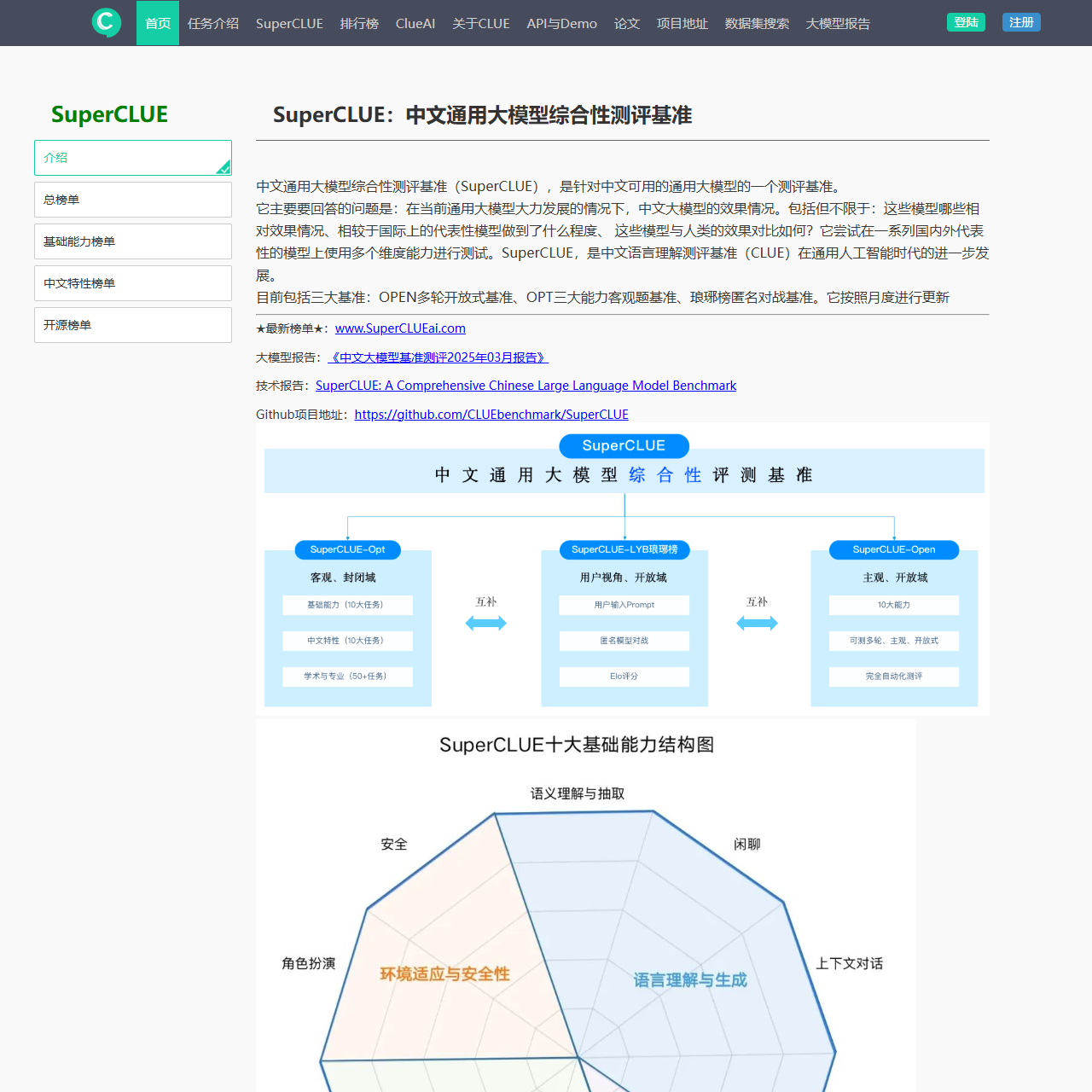
| SuperCLUE |
SuperCLUE综合评测、总榜单1.1/1.0、基础能力榜单、中文特性榜单、开源榜单 |
中文大模型综合性能测评基准,涵盖各类NLP任务 |
| 报告与文档 |
《中文大模型基准测评2025年03月报告》、SuperCLUE: A Comprehensive Chinese Large Language Model Benchmark、https://github.com/CLUEbenchmark/SuperCLUE、CLUEbenchmark@163.com |
官方报告与文档,便于学术引用与模型理解 |
| 首页 |
任务介绍、最新榜单、排行榜、登陆注册 |
入口页面,概览网站核心功能与资源 |
| 模型列表 |
GPT-4、文心一言(v2.2.0)、Claude-2、gpt-3.5-turbo、ChatGLM-130B、讯飞星火(v1.5)、Claude-instant-v1、360智脑(4.0)、internlm-chat-7b、ChatGLM2-6B、MiniMax-abab5.5、通义千问(v1.0.3)、Baichuan-13B-Chat、BELLE-LLaMA-13B-2M-enc、IDEA-姜子牙-13B-v1.1、phoenix-7B、MOSS-16B、Llama-2-13B-chat、Vicuna-13B、RWKV-7B-World-CHNtuned |
展示可测评的各类中文大模型,便于用户选择与比较 |
盾灵安全导航
SuperCLUE使命:精准量化AGI进展,定义人类迈向AGI路线图
CLUE定位:为更好的服务中文语言理解、任务和产业界,做为通用语言模型测评的补充,通过搜集整理发布中文任务及标准化测评等方式完善基础设施,最终促进中文NLP的发展。
内容体系:代表性的数据集、基线(预训练)模型、语料库、论文、工具包、排行榜。